
I was asked to do a historic analysis of SQL Server jobs to determine their statistics, such as the number of runs, average run duration, successes/failures etc. As part of the daily checks I do on a server I’d only check the job runs for the past 24 hours. So I was surprised when I started the analysis and saw that averages for the same job across servers varied significantly.
When I looked at the msdb.dbo.sysjobhistory table of the server with the lowest averages I noted that there were only 999 rows and the history only went back a day or two.
So I had effectively no history on that server. When I looked at another the sysjobhistory table had almost 10 million entries, roughly 4 Gb of data! (The joys of taking over someone else’s environment)
This got me looking at the history settings for the SQL Agent. To open the SQL Server Agent Properties while in SQL Server Object Explorer right click on SQL Server Agent and then click on properties.
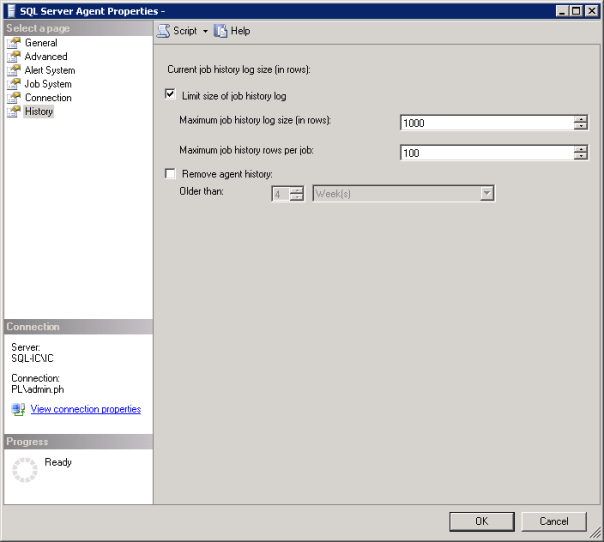
For the first server the history settings were set to the default of 1000 lines for the log as a whole and 100 lines for the individual jobs. If you have a job that runs 4 steps that will use 5 lines, one line for the job and one line for each of the steps that are run. When I looked at the history settings on the second, server as you would expect, no settings had been applied.
Some sensible thresholds needed to be applied across the environment. I’m not going to dictate to you what your retention policy should be regarding job run history but I will say it can be as much as business decision as a server maintenance one so ask around if people need a record that something has run.
You may be in the position that you can be specific enough to enter row values but most organisations will have jobs that run weekly or monthly. In that case you may be better off using the “Older than” option and setting a retention period rather than using rows.
Always with logging, if you have the space, you’re better off having too much than having too little and missing data you need. The size of each row in the sysjobhistory table is at most 4.5KB so keeping 10k rows is only around 45 Mb. If you don’t have 45 Mb to spare on your server then job history retention is the least of your worries. The worst thing that is likely to happen in storing more rows than you need is that it takes a bit longer to bring up the job history viewer. But here’s a link to some queries to help with that.
The moral of the story is just because it’s in the MSDB doesn’t mean Microsoft are taking care of it. Check your settings and make sure you’re retaining an appropriate amount of history now.


