Summary
Among data specialist that do not work in the field of Big Data there can be confusion surrounding the term Data Lake. This is because there is apparent overlap in terms of role and function between Data Lakes and, the more traditional, Data Warehouses the likes of which data professionals will be more familiar with. This confusion is not helped by the term Data Lake itself being overloaded which will be discussed later in this article. However despite this overlap Data Lakes do occupy their own distinct role and perform functions Data Warehouses cannot.
Data Lakes have tremendous utility but damagingly there is also a mass of literature surrounding Data Lakes pushing the concept as a cure-all that coincidentally will also require you to migrate your organizations Business Intelligence center into the cloud. The following statements will hopefully dispel some of the associated hucksterism.
- Data Lakes are not Data Warehouses 2.0, i.e. they are not the evolution of a Data Warehouse.
- Data Lakes have not replaced Data Warehouses in performing the role of housing aggregated data.
- Data Lakes will not free you from the burden of developing ETLs or establishing robust Data Architecture and strong Data Governance.
Introduction
It is important to first clarify that both Data Warehouses and Data Lakes are abstract concepts independent of any particular software or vendor. A Data Warehouse can be created in any database engine such as SQL Server, PostgreSQL, Oracle or MySql. Similarly a Data Lake can be deployed across any suitably large data storage platform, i.e. an on-site data center or hosted in the cloud.
In basic terms both Data Warehouses and Data Lakes can be thought of as the place where all data relevant to an organization’s goals is pulled together from various sources both internal and external (increasingly external). They both exist to facilitate an all encompassing view of an organization and how will it performs or provide a greater understanding of the organization’s environment, opportunities (e.g. customer preferences and habits) and threats. However they differ in terms of the data they are optimized to handle and are therefore better suited to different use cases.
What is a Data Warehouse?
A Data Warehouse is a method for storing and organising data that is optimized to support Business Intelligence (BI) activities such as analytics. To put it another way they solely exist and are constructed in a manner to best answer big questions efficiently. For this reason they typically hold vast quantities of historical data. The data within a data warehouse is usually derived from a wide range of sources such as application log files but primarily transaction applications (Oracle, 2019). However in contrast to a transactional database were each transaction is a separate record, the relevant entries in a Data Warehouse are typically aggregated although they can also hold transaction records for archival purposes.
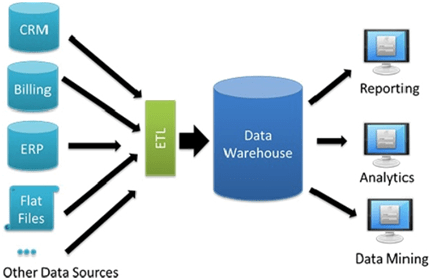
Figure 1: Typical Data Warehouse architecture of an SME (Databricks, 2019)
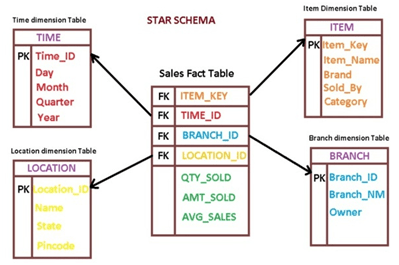
Single transaction records on their own are not typically very insightful to an organization, trying to identify consumer trends for example. Aggregating data based on facts and dimensions, e.g. the number of sales (fact) for a particular store (dimension), saves disk space and allows queries looking for that specific answer to be returned quickly. Data Warehouses mostly contain numeric data which is easily manipulated. As an example store sales might be the summation of thousands of rows of data to a single row.
Figure 2: Simplified example of a Data Warehouse internal structure (BIDataPro, 2018)
Data Warehouses also solve the problem of trying to derive information when there are too many sources, e.g. a multinational with thousands of store locations and subsidiaries, by creating a “single source of truth”. Effectively this means pulling all the information to one central location, transforming the data for uniformity and storing like for like data together. For example this could mean gathering all sales data from multiple locations and converting the currency to dollars. All of the data in one place together allows for different sources, which serve different purposes, to be combined via a single query. For example a report that links sales data and logistical data, coming from POS and SCM systems respectively, may not be possible with a single query if the systems are not linked. If best practices regarding I.T. security are being followed they certainly should not be.
Data Warehouses are fed from source systems using an extract, transform and load (ETL) solution. This means data is extracted from a source system, transformed to meet schema and business requirements of the Data Warehouse and then loaded. This is a data delivery method independent of any particular software vendor. There are various software to accomplish ETLs including the option to create a custom application. A variation of this process is extract, load and transform (ELT) in which the data is landed into tables raw and later transformed to meet the schema and business requirements of their intended final table. This method allows for greater auditability which could aid in regulatory compliance or post-mortems if the transformation process fails.
Once set up the Data Warehouse can facilitate statistical analysis, reporting, data mining and more sophisticated analytical applications that generate actionable information by applying machine learning and artificial intelligence (AI) algorithms (Oracle, 2019).
For an organization a single source of truth which will eliminate inconsistencies in reporting, establish a single set of global metrics and allow everyone in the organization to “sing from the same hymn sheet” is very important due to how beneficial the information provided is in directing informed decisions.
So if Data Warehouses have proven such an excellent platform for generating information why are alternatives needed? Well by design only a subset of the attributes are examined, so only pre-determined questions can be answered (Dixon, 2010). Also the data is aggregated so visibility into the lowest levels is lost (Dixon, 2010). The final major factor is that some of the most vital sources of information are no longer simply numerical in nature and generated by an organizations internal transactional system. So what has changed?
The Digital Universe
The data landscape has changed drastically in just a few short years. Like the physical universe, the digital universe is large and growing fast. It was estimated that by 2020 there would be nearly as many digital bits as there are stars in the observable universe (Turner, 2014). That estimate is somewhere in the region of 44 zettabytes, or 44 trillion gigabytes (Turner, 2014). Even though this quantity of data is already beyond human comprehension the rate of growth is probably the more impressive feat. For context there is over 10 times more data now than there was in 2013 when the digital universe was an estimated 4.4 zettabytes (Turner, 2014). The data we create and copy annually is estimated to reach 175 zettabytes by 2025 (Coughlin, 2018).
Where is all this data coming from?
The short answer is predominately us and the systems that service our needs. In the not too distant past the only entities to have computers generating and storing data were businesses, governments and other institutions. Now everyone has a computer of some description and with the advent of social media mass consumers became mass creators. When you stop to think of how many interactions a person has with electronic devices every day, directly or indirectly, you soon get a picture of how much data is actually being generated.
As an example of this endless generation of data the following are average social media usage stats over the course of one minute from 2018 (Marr, 2018):
- Twitter users sent 473,400 tweets
- Snapchat users shared 2 million photos
- Instagram users posted 49,380 pictures
- LinkedIn gained 120 new users
Other extraordinary data stats include (Marr, 2018):
- Google processes more than 40,000 searches every second or 3.5 billion searches a day.
- 5 billion people are active on Facebook every day. That’s one-fifth of the world’s population.
- Two-thirds of the world’s population now owns a mobile phone.
Our way of life has become increasingly digitized with no better example than the effective global lockdown during the 2020 pandemic. Hundreds of millions of employees from around the world managed to continue working from home and did so effectively (Earley, 2020). This would have been unimaginable even by the late nineties. And yet as digitized as our world has become it is only the start. With emerging technologies such as self-driving cars, IoT smart devices and ever increasingly sophisticated robots entering our homes the 175 zettabytes of data by 2025 maybe a conservative estimate.
With so much of the stuff you would be forgiven for thinking all of this data is just a by-product but it is anything but. The data generated is an incredibly valuable asset if it can be analyzed properly and transformed into business relevant information.
What types of data are there?
The state of data within the digital universe can be summarized as structured, semi-structured and unstructured (Hammer, 2018).
The following is a non-exhaustive list of data types (Hammer, 2018):
- CRM
- POS
- Financial
- Loyalty card
- Incident ticket
- Email
- PDF
- Spreadsheet
- Word processing
- GPS
- Log
- Images
- Social media
- XML/JSON
- Click stream
- Forums
- Blogs
- Web content
- RSS feed
- Audio
- Transcripts
Only the data types above in bold are suitable for aggregation (Hammer, 2018). The rest of the data types are typical of what now makes up a large proportion of the digital universe, and despite their value as data assets they are not suitable for storage or analysis within a Data Warehouse. This is because data needs to meet the predefined structure of a Data Warehouse in order for it to be accepted and aggregating these raw unstructured files, e.g. video and audio files etc., is not possible. So how are these types of valuable data turned into actionable information?
What is a Data Lake?
Data Warehouses have been utilized by data specialists for decades but the concept of Data Lakes is much more contemporary and much better suited to deal with storage, analysis and analytics of the semi-structured and unstructured data listed above. By design storage within a Data Lake of these kinds of data does not require files to be transformed as the file is kept in a raw state. Files can be simply copied from one file structure to another. Data Lakes also allow for working off the files directly which means the data can be used effectively immediately, i.e. as soon as it lands, rather than waiting weeks for the Data Warehouse developers to massage the data into a format that the data warehouse can accept if that is even possible (Hammer, 2018). Working with this type of data has become synonymous with the field of Big Data, which is defined by high velocity, high volume and high variability. As such the two methodologies of Data Warehouses and Data Lakes are not necessarily in competition with each other either, in fact depending on their definition (Data Lake is somewhat of an overloaded term (Bethke, 2017)) they could be argued to resolve difference problems and can complement each other when deployed within the same architecture.
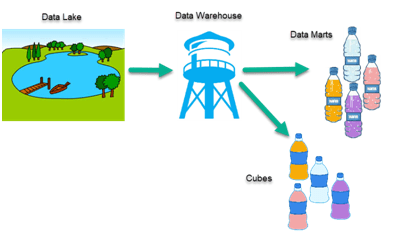
There is some contention as to the definition of a Data Lake. Some would argue that original meaning implied the Lake was a raw data reservoir solely (Bethke, 2017). By this definition the Data Lake is not too dissimilar to a staging area or Operational Data Store (ODS) in a data warehouse were raw copies of data from source systems are landed (Bethke, 2017). This would coincide with an ELT process as opposed to an ETL process. The transform and integration of the data happens later downstream during the populating of the data warehouse (Bethke, 2017). This understanding of a Data Lake still persists today in the minds of many data specialist as can be seen below in the overly simplified illustration.
Figure 3: Overly simplified illustration of a Data Lake architecture (Hammer, 2018)
(Note: no indication of analysis being performed on the lake directly, the lake services the warehouse solely)
However it is an inaccurate understanding as the person who is credited with coining the term, James Dixon, used the following analogy when he explained a Data Lake:
“If you think of a datamart as a store of bottled water – cleansed and packaged and structured for easy consumption – the data lake is a large body of water in a more natural state. The contents of the data lake stream in from a source to fill the lake, and various users of the lake can come to examine, dive in, or take samples.” (Dixon, 2010)
By stating “various users of the lake can come to examine, dive in, or take samples” Dixon is clearly implying that a feature of the Data Lake is that it is accessible prior to the data being transformed and made available in a Data Warehouse.
This is where Data Lakes and Data Warehouses take an opposing strategy on applying structure to data which is perhaps why they are often mistaken as alternative competing concepts to each other. A Data Warehouse requires Schema on Write whereas a Data Lake uses Schema on Read.
With schema on write all of the relevant data structure needs to be prepared in advance which means all of the relevant business questions need to be thought of in advance. This rarely results in a situation where all the relevant stakeholders have their needs met and if they do it will not be for very long. This scenario is workable by an organization looking to aggregate finance data they are very familiar with but it is especially difficult when dealing with Big Data were the questions are unknown.
With schema on read the schema is only applied when the data is read allowing for a schema that is adaptable to the queries being issued. This means you are not stuck with a predetermined one-size-fits-all schema (Pasqua, 2014). This allows for the storage of unstructured data and since it is not necessary to define the schema before storing the data it makes it easier to bring in new data sources on the fly. The exploding growth of unstructured data and overhead of ETL for storing data in RDBMS is the offered as a leading reason for the shift to schema on read (Henson, 2016).
When dealing with Big Data the problem of a predefined schema can be so burdensome that it can sink a data project or increase the time-to-value past the point of relevance (Pasqua, 2014). Using a schema on read approach on data as-is means getting value from it right away (Pasqua, 2014). The flexibility of Data Lakes in this regard allows them to surpass Data Warehouses in terms of scalability while making data accessible for analysis sooner.
Data Lakes Scalability
By using schema on read the constraint on scale is virtually removed. The threat of a bottleneck still exists but now in the form of physical constraints in terms of the hardware available. This is why online cloud offerings such as Amazon S3 and Azure Data Lake from Microsoft have become so popular. Of course on-site data centers are also an option with Hadoop being a very popular solution which combines a Data Lake structure with analytically capabilities. This level of scalability also safe guards against Data Silos. A Data Silo is an undesirable situation where only one group or a limited number of people in an organization have access to a source of data that has a broader relevance to people across an organization (Plixer, 2018).
Data Lakes are intended by design and philosophy to be an antithesis to Data Silos where all an organizations data is stored together in one lake. However centrally storing all data is not without significant security concerns and losing sight of what customer data is on hand can run afoul of numerous legal requirements such as GDPR.
Data Lakes Analysis & Analytics
A defining feature of Big Data analytics is the concept of bringing the analytics to the data rather than the data to the analytics. Traditionally analytics was carried out by feeding single flat files into an algorithm with the time taken to prepare these files being significant. Although accessing the raw files directly is potentially a failing as it has the potential to break the principle of a single source of truth and therefore runs the risk of introducing inconsistencies between reports and other forms of analysis. As you can imagine this is complex and disciplined work which is why Data Lakes, at this point in their maturity, are best suited to Data Scientists and advanced Data Analysts (Hammer, 2018). However this goes against the Data Lake ethos of “data for all” as it only allows the very skilled to have access. This creates the problem Data Lakes were meant to solve by imposing restrictions or “data for the select few”. With Data scientists acting as the gatekeepers an organizations stakeholders can lose sight of the useful data available to them. Worse still is that valuable data may come from external sources with stakeholders having no visibly of it prior to it landing in the Data Lake. This may leave stakeholders with no option but to take action based on an analysis produced by a Data Scientist with accuracy of the analysis being a matter of fate because the stakeholder has no data to say otherwise. In comparison the creation of a Data Warehouse is usually a collaboration of stakeholders, familiar with internal sources systems and data, and developers. Once a Data Warehouse is created, far less skilled (and cheaper) Data Analysts will have the ability to navigate the internal structure and compile valuable reports.
Despite the obvious concerns the significance of scalability and direct raw data analysis cannot be overlooked. The sooner an organization is informed the sooner it can act. In real world terms this could save millions of dollars, save thousands of jobs or stop the organizations itself from going under. However the benefits of scalability and earlier data access are not without risks as poorly managed Data Lakes have the potential to turn into Data Swamps. Data Swamps are poorly managed Data Lakes that become a dumping ground for data. Though the data may be unstructured the method in which it is stored must not be or visibility of what is stored and where it is stored will be lost. Failure to catalogue the data, letting users know what is available while making the attributes of the data known, will overwhelm users and result in the garbage results (Hammer, 2018). Successful implementation of a Data Lake is complex and requires ongoing commitment to maintain but for a large organization that needs to make better use of the wider range of data available in the digital universe a Data Lake is a necessity.
Conclusion
A Data Lake is not a replacement for a Data Warehouse. Data Lakes are better equipped to solve the different problems associated with dealing with semi-structured to unstructured data. Their flexibility in this regard allows them to surpass Data Warehouses in terms of scalability while making data accessible for analysis sooner. However Data Lakes are not without their drawbacks. They require highly skilled and expensive staff to develop and maintain. They potentially run a greater risk of failing spectacularly by devolving into a Data Swamp and could potentially become a serious liability from a regulatory standpoint if this was to happen. Organisations can also be left at the mercy of Data Scientists in how accurate they are in analyzing data and producing correct reports as stakeholders may not have the expertise to retrieve data from the Data Lake themselves.
Thankfully Data Warehouses are still perfectly suited for dealing with numeric data and for organizations that still predominately use their own internal transactional systems in the creation of actionable information these organisations have no immediate need to utilize any alternatives.
References:
Bethke, U. (2017) ‘Are Data Lakes Fake News?’, Sonra, 8 August. Available at: http://www.kdnuggets.com/2017/09/data-lakes-fake-news.html (Accessed: 4 July 2020).
BIDataPro (2018) ‘What is Fact Table in Data Warehouse’, BIDataPro, 23 April. Available at: https://bidatapro.net/2018/04/23/what-is-fact-table-in-data-warehouse/ (Accessed: 4 July 2020).
Coughlin, T. (2018) 175 Zettabytes By 2025, Forbes. Available at: https://www.forbes.com/sites/tomcoughlin/2018/11/27/175-zettabytes-by-2025/ (Accessed: 4 July 2020).
Databricks (2019) ‘Unified Data Warehouse’, Databricks, 8 February. Available at: https://databricks.com/glossary/unified-data-warehouse (Accessed: 4 July 2020).
Dixon, J. (2010) ‘Pentaho, Hadoop, and Data Lakes’, James Dixon’s Blog, 14 October. Available at: https://jamesdixon.wordpress.com/2010/10/14/pentaho-hadoop-and-data-lakes/ (Accessed: 4 July 2020).
Earley, K. (2020) Google and Facebook extend work-from-home policies to 2021, Silicon Republic. Available at: https://www.siliconrepublic.com/companies/google-facebook-remote-work-until-2021 (Accessed: 5 July 2020).
Hammer, D. (2018) What is a data lake? – The Hammer | The Hammer. Available at: https://www.sqlhammer.com/what-is-a-data-lake/ (Accessed: 4 July 2020).
Henson, T. (2016) ‘Schema On Read vs. Schema On Write Explained’, Thomas Henson, 14 November. Available at: https://www.thomashenson.com/schema-read-vs-schema-write-explained/ (Accessed: 6 July 2020).
Marr, B. (2018) How Much Data Do We Create Every Day? The Mind-Blowing Stats Everyone Should Read, Forbes. Available at: https://www.forbes.com/sites/bernardmarr/2018/05/21/how-much-data-do-we-create-every-day-the-mind-blowing-stats-everyone-should-read/ (Accessed: 5 July 2020).
Oracle (2019) What Is a Data Warehouse | Oracle Ireland. Available at: https://www.oracle.com/ie/database/what-is-a-data-warehouse/ (Accessed: 5 July 2020).
Pasqua, J. (2014) Schema-on-Read vs Schema-on-Write, MarkLogic. Available at: https://www.marklogic.com/blog/schema-on-read-vs-schema-on-write/ (Accessed: 6 July 2020).
Plixer (2018) What is a Data Silo and Why is It Bad for Your Organization? Available at: https://www.plixer.com/blog/data-silo-what-is-it-why-is-it-bad/ (Accessed: 6 July 2020). Turner, V. (2014) The Digital Universe of Opportunities. Available at: https://www.emc.com/leadership/digital-universe/2014iview/executive-summary.htm (Accessed: 5 July 2020).