The use case for this batch script is to monitor SQL Server files using Windows task manager scheduled to run the file every 5 minutes. The batch scripts gathers the stats of every file in a referenced directory. The script can obviously be adapted however to something that suits your specific needs.
Note: Running this script against the C drive on a laptop took 15 minutes and produced a text file that was around 50 Mb. The script is best utilized in scenarios such as monitoring file sizes on drives used by applications that do not generate thousands of files, e.g. backup directories etc.
There is two scripts presented below. The first is the simpler of the two scripts, it just records the file stats of a single directory.
Directions for use:
Take either script below and save it as a batch file called FileStatsLogger.
Two variables need to be updated to use the script:
“LogPath=C:\Log\” Change C:\Log\ to another directory if you want the output file written somewhere else.
“ScanDir=C:\FolderToScan\” Change C:\FolderToScan\ to the directory you want to gather file stats from.
The file that will be created, FileStats, will record the following information:
- A timestamp of when the batch script was run
- A reference to each parent directory
- Every file creation date and time
- File size in Kbs
- Every file owner
- The name of the file
- How many files are in the directory and their collective size
The output file will look like this when opened.
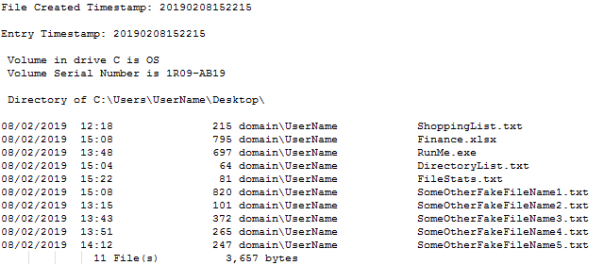
Each time the script is run it will update the text file FileStats.
@ECHO OFF
REM SET TIMESTAMP VARIABLE
SET Timestamp=%date:~6,8%%date:~3,2%%date:~0,2%%time:~0,2%%time:~3,2%%time:~6,2%
REM SET FILE LOGGING VARIABLES
SET "LogPath=C:\Log\"
SET "LogFileName=FileStats.txt"
SET "Log=%LogPath%%LogFileName%"
SET "ScanDir=C:\FolderToScan\"
REM CREATE FILE IF DOES NOT EXIST
IF NOT EXIST "%Log%" ECHO File Created Timestamp: %Timestamp% > "%Log%"
REM TIMESTAMP ENTRY
ECHO/ >> "%Log%"
ECHO Entry Timestamp: %Timestamp% >> "%Log%"
ECHO/ >> "%Log%"
REM SCAN DIRECTORY
DIR /a %ScanDir% >> %Log%
To scan multiple directories create a text file called DirectoryList and populate the the file with the directories you want to scan. Each directory on a new line, for example:
L:\
D:\
T:\
It is assumed the directory list text file will be kept in the same directory as the batch file FileStatsLogger but you should add the full file path to were DirectoryList.txt is referenced in the script to avoid any problems.
Note: L, D & T are the naming convention for the Log, Data and tempdb drive names for SQL Server. These are just drive letters examples but you can be more specific like C:\Users\UserName\Desktop\ just be sure to include the backslash at the end of the reference.
This script will create a new log file for each day as the files can be large. The filename will following the format FileStats_YYYYMMDD.
As before you will have to:
“LogPath=C:\FileStats\” Change C:\Log\ to another directory if you want the output file written somewhere else.
“ScanDir=C:\FileStats\DirectoryList.txt” Change to the directory you will store DirectoryList.txt.
Though it is recommended you keep everything in a folder like this (potentially writing the FileStats log to a directory off of the host server):
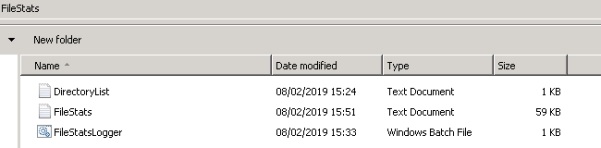
@ECHO OFF
REM SET TIMESTAMP VARIABLES
for /f "tokens=2 delims==" %%G in ('wmic os get localdatetime /value') do set datetime=%%G
SET "dd=%datetime:~6,2%"
SET "mth=%datetime:~4,2%"
SET "yyyy=%datetime:~0,4%"
SET "hh=%time:~0,2%"
SET "mm=%time:~3,2%"
SET "ss=%time:~6,2%"
SET "FileNameDate=%yyyy%%mth%%dd%"
SET "Timestamp=%yyyy%%mth%%dd%%hh%%mm%%ss%"
REM SET FILE LOGGING VARIABLES
SET "LogPath=c:\FileStats\"
SET "LogFileName=FileStats_%FileNameDate%.txt"
SET "Log=%LogPath%%LogFileName%"
REM CREATE FILE IF DOES NOT EXIST
IF NOT EXIST "%Log%" ECHO File Created Timestamp: %Timestamp% > "%Log%"
REM TIMESTAMP ENTRY
ECHO/ >> "%Log%"
ECHO Entry Timestamp: %Timestamp% >> "%Log%"
ECHO/ >> "%Log%"
REM READ DIRECTORY LIST AND SCAN EACH DIRECTORY REFERENCED
FOR /f "tokens=*" %%x IN (c:\FileStats\DirectoryList.txt) DO DIR /a /s /q "%%x" >> %Log%
Finally you can create a Windows task scheduler task to run the script at an interval that suits your needs.
The description of the task could be something along the lines of:
This task runs the batch script “FileStatsLogger” every 5 minutes which
logs the stats for each file of each directory referenced in the file
Directory List. The stats are recorded in the FileStats txt file.
All resources related to this tasks are contained in the FileStats directory.


